|
Maschinelles Lernen hilft bei der Auswertung von Gaia-Daten
Redaktion
/ Pressemitteilung des Leibniz-Instituts für Astrophysik Potsdam (AIP)
astronews.com
10. Oktober 2024
Mithilfe eines neuartigen maschinellen Lernmodells konnten
nun Beobachtungsdaten des Astrometriesatelliten Gaia von 217 Millionen Sternen
effizient verarbeitet werden. Es zeigte sich, dass die Ergebnisse den
herkömmlichen Methoden zur Ermittlung von Sternparametern durchaus ebenbürtig
sind. Die Auswertung benötigte aber nur einen Bruchteil der Rechenzeit.
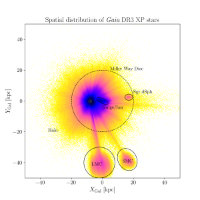
Großskalige Karte (330.000 Lichtjahre
Kantenlänge) der Sterndichte von 217 Millionen
Sternen der Gaia DR3 XP Daten in
galaktozentrischen, kartesischen Koordinaten. Der
weiße Kreis markiert unsere Position in der
Milchstraße, die weiter entfernten dichten
Regionen (rosa Flecken) sind die Kleine und die
Große Magellansche Wolke (LMC und SMC) und die
Sagittarius Zwerggalaxie (Sgr dSph).
Bild:
F. Anders (Universitat de Barcelona) [Großansicht] |
Mit der dritten Datenveröffentlichung des Gaia-Satelliten der
europäischen Weltraumorganisation ESA erhielten Astronominnen und Astronomen
Zugang zu verbesserten Messungen für 1,8 Milliarden Sterne – eine riesige Menge
an Daten für die Erforschung der Milchstraße. Die effiziente Analyse eines so
großen Datensatzes stellt jedoch eine Herausforderung dar. In einer jetzt
veröffentlichten Studie untersuchten Forschende unter Leitung des
Leibniz-Instituts für Astrophysik Potsdam (AIP) und des Institut de Ciéncies
del Cosmos an der Universität Barcelona (ICCUB) den Einsatz von
maschinellem Lernen zur Bestimmung wichtiger Sterneigenschaften anhand der
spektrophotometrischen Daten von Gaia. Das Modell wurde auf qualitativ
hochwertigen Daten von acht Millionen Sternen trainiert und erzielte
zuverlässige Vorhersagen mit geringen Unsicherheiten.
"Die zugrunde liegende Technik, 'Extreme Gradient-Boosted Trees' genannt,
ermöglicht die Ermittlung präziser stellarer Eigenschaften wie Temperatur,
chemische Zusammensetzung und interstellare Staubverdunkelung mit einer bisher
unerreichten Effizienz. Das entwickelte maschinelle Lernmodell, SHBoost,
erledigt seine Aufgaben, einschließlich Modelltraining und Vorhersage, innerhalb
von vier Stunden auf einem einzigen Grafikprozessor – ein Vorgang, für den zuvor
zwei Wochen und 3000 Hochleistungsprozessoren erforderlich waren", sagt Arman
Khalatyan vom AIP. "Die Methode des maschinellen Lernens reduziert somit die
Rechenzeit, den Energieverbrauch und den CO2-Ausstoß erheblich."
Dies ist das erste Mal, dass eine solche Methode erfolgreich für alle
Sterntypen gleichzeitig eingesetzt wurde. Das Modell wird mit hochwertigen
spektroskopischen Daten aus kleineren Himmelsdurchmusterungen trainiert und
wendet diese Erkenntnisse dann auf den großen Datensatz der dritten
Datenveröffentlichung von Gaia (DR3) an. Dabei werden die wichtigsten
Sterneigenschaften nur mithilfe der photometrischen und astrometrischen Daten
sowie den niedrig aufgelösten XP-Spektren von Gaia gewonnen. "Die hohe Qualität
der Ergebnisse reduziert die Notwendigkeit zusätzlicher ressourcenintensiver
spektroskopischer Beobachtungen auf der Suche nach guten Kandidaten für weitere
Untersuchungen, wie z. B. seltene metallarme oder supermetallreiche Sterne, die
für das Verständnis der frühesten Phasen der Entstehung der Milchstraße
entscheidend sind", sagt Christina Chiappini, ebenfalls Wissenschaftlerin am
AIP.
Dies erweist sich als entscheidender Vorteil für die Vorbereitung künftiger
Beobachtungen mit Multi-Objekt-Spektroskopie, wie z. B. das Projekt 4MIDABLE-LR,
eine große Durchmusterung der galaktischen Scheibe und des Bulge, der zentralen
Verdickung der Milchstraße, die Teil des 4MOST-Projekts an der Europäischen
Südsternwarte (ESO) in Chile sein wird. "Der neue Modellansatz liefert
umfassende Karten der gesamten chemischen Zusammensetzung der Milchstraße und
bestätigt die Verteilung von jungen und alten Sternen. Die Daten zeigen die
Konzentration metallreicher Sterne in den inneren Regionen der Galaxie,
einschließlich des Balkens und des Bulge, mit einer enormen statistischen
Aussagekraft", fügt Friedrich Anders vom ICCUB hinzu.
Das Team nutzte das Modell auch, um junge, massereiche, heiße Sterne in der
gesamten Galaxie zu kartieren und zeigte dabei entfernte, bisher kaum
untersuchte Sternentstehungsregionen auf. Die Daten enthüllen auch, dass es in
unserer Milchstraße eine Reihe von "stellaren Leerräumen" gibt, also Gebiete,
die nur sehr wenige junge Sterne beherbergen. Außerdem wird aus den Daten
ersichtlich, wo bisher die dreidimensionale Verteilung von interstellarem Staub
noch unzureichend aufgelöst ist.
Da Gaia weiterhin Daten sammelt, macht die Fähigkeit von Modellen
des maschinellen Lernens, die riesigen Datensätze schnell zu verarbeiten, diese
zu einem unverzichtbaren Werkzeug für die zukünftige astronomische Forschung.
Der Erfolg dieses Ansatzes zeigt das Potenzial des maschinellen Lernens, die
Analyse großer Datenmengen in der Astronomie und anderen wissenschaftlichen
Bereichen zu revolutionieren und gleichzeitig nachhaltigere Forschungspraktiken
zu fördern.
Über ihre Ergebnisse berichtet das Team in einem Fachartikel, der in der
Zeitschrift Astronomy & Astrophysics erschienen ist.
|





